L’Eurozona, la Ue, poi i paesi “core”, quelli periferici, persino i “Pigs”, i maiali… Come il mondo, articolato in tanti gruppi definiti con criteri molto eterogenei, anche l’Europa ha le sue divisioni, e anche per il Vecchio continente – come è stato fatto per l’intero pianeta – può aver senso affidare a un software una suddivisione rigorosa sulla base di alcuni parametri non arbitrari (ma sicuramente discrezionali).
Nel contesto globale, l’Europa veniva smembrata in otto gruppi diversi. Francia e Germania da una parte, l’Italia, la Spagna e la Gran Bretagna in un’altra, un folto gruppo nell’insieme dei paesi che possono essere definiti di transizione, e persino alcuni tra gli emergenti (la Romania e la Turchia al fianco del Messico, alcuni balcanici con Cina e Brasile). La Moldavia finiva addirittura tra i paesi meno sviluppati.
È possibile però effettuare una suddivisione più dettagliata dei soli paesi europei (Turchia e Russia compresi, per quanto la cosa possa essere controversa, e con l’assenza della Bielorussia in mancanza di dati sufficienti). Per questo insieme si può aggiungere ai dati già utilizzati per l’esperimento precedente – che come questo, va ripetuto, è poco più di un gioco – anche la disoccupazione (media ventennale), disponibile per tutti i paesi. (Gli altri sono la media ventennale della crescita del pil reale, dell’inflazione e del disavanzo commerciale con l’estero in rapporto con il pil, poi gli ultimi dati disponibili del pil pro capite a parità di potere d’acquisto, al quale è stato dato un peso maggiore per rendere il risultato più riconoscibile, della popolazione, e del debito pubblico in rapporto al pil insieme alla sua variazione in punti percentuali degli ultimi 20 anni. Sono tutti dati Fmi).
Il metodo usato per il mondo intero si rivela però inutilizzabile per il Vecchio Continente. Il software si mostra “incerto”: ripetendo la procedura più volte, come è opportuno fare, dà risultati quasi sempre diversi. Un sistema alternativo dà invece risultati stabili e interessanti. Nel senso che il Vecchio continente ne emerge riconoscibile ma con qualche interessante “anomalia” rispetto alle comune suddivisioni.
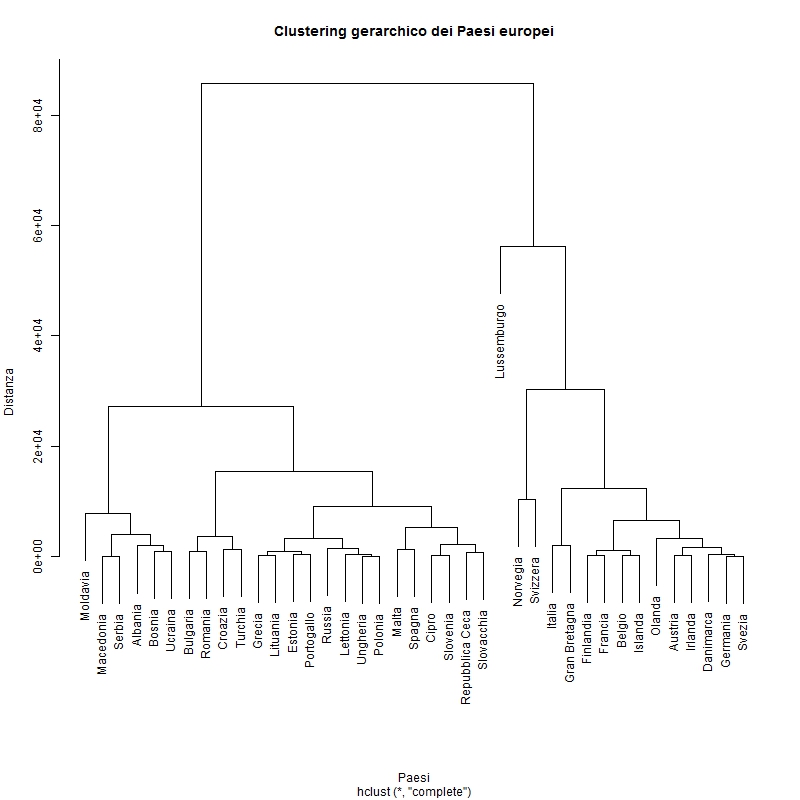
Due i gruppi principali, definiti dal software in base a una “vicinanza” che di per sé non permette una gerarchia in termini di sviluppo economico. È un fatto però che i paesi avanzati si trovino tutti raccolti in un insieme mentre gli altri, che si possono quindi chiamare “paesi in transizione” o “periferici”, sono accomunati in un secondo insieme che però comprende tra gli altri non solo la Grecia, ma sorprendentemente anche la Spagna – vicinissima a Malta – e il Portogallo. Eurolandia è dunque divisa davvero in due, e tra i periferici ci sono anche i Baltici, più Slovenia e Slovacchia.
Nei paesi in transizione non sorprende invece trovare vicini tra loro i Balcanici meno sviluppati, e poi la Romania e la Bulgaria, mentre la “parentela” tra Croazia e Turchia dà il senso dei progressi (economici) del paese eurasiatico. Sono a brevissima distanza, senza sorprese, Ungheria e Polonia da una parte – con la Russia, un po’ più lontana, non molto distante – e poi Slovenia e Cipro con Repubblica Ceca e Slovacchia dall’altra. Piuttosto lontane, economicamente, Mosca e Kiev, ma anche Grecia e Cipro.
L’Italia è invece nel “core” dell’Europa. Vicinissima alla Gran Bretagna, un po’ più lontana dal gruppo di paesi davvero centrale composto da Germania e Svezia al quale si aggregano via via la Danimarca, l’Irlanda e l’Austria molto vicine tra loro, e – un po’ più distaccate – Islanda e Belgio con Finlandia e Francia.
La cosa più sorprendente è che, al di là della maggiore ricchezza dei dettagli e a parte il caso della Spagna, i risultati sono quasi del tutto sovrapponibili, e in ogni caso compatibili, con quelli individuati – attraverso una metodologia diversa e con il dato della disoccupazione assente – con quelli ricavati dall’analisi del mondo interno descritta nel precedente post. L’anomalia spagnola, tra l’altro, non scompare se dai dati di partenza viene eliminato l’indicatore relativo al mercato del lavoro aggiunto per questa seconda elaborazione.
Nota tecnica: l’elaborazione, un clustering gerarchico con distanza euclidea e linkage completo è stata effettuata con linguaggio di programmazione R, versione, 3.1.3, su sistema operativo Windows 7 Professional. A tutti i dati, con l’eccezione del Pil pro capite che fa da base (senza annullare il peso degli altri indicatori), è stata applicata una trasformazione di scala in modo da attribuire una media zero e una deviazione standard pari a uno. L’elaborazione è stata realizzata in tutte le sue fasi dall’autore del post.


